create optimized wordlist data structures for mobile webapps

John Resig (creator and lead developer of jQuery) has published two interesting articles about data structure for a lookup to a huge wordlist (dictionary lookups and trie performance). Read in his articles about all the variants and preconditions.
I implemented six variants for the data structure (started with simple String search, Array to Trie) and benchmarked them to find the best solution. But let’s start with the rules:
1. loading time
The data structure should be as short as possible and available as an JavaScript file from a CDN. I created the complete data variants with python and uploaded the files on the google app engine (caching header and gzip as default).
2. memory usage
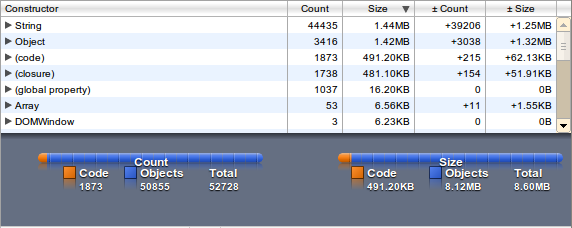
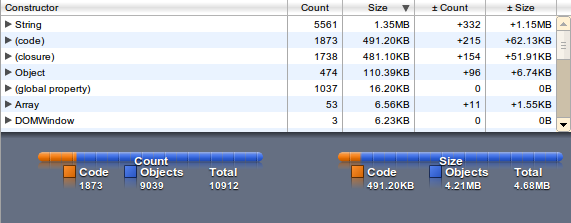
You can transfer a compressed data structure and extract it in the client. This can double your memory usage. Limit and test the memory usage - it should run on mobile devices with limited memory and cpu. I added the heap snapshots from the chrome developers tools to get the usage in an browser (John does it with node.js).
3. fast access
Find the existence of given word (or only his word stem) in the wordlist - the function for searching have to be benchmarked. I included an interactive page with loading the data files and a JSLitmus benchmark.
- wordlist = ["works", "worksheet", "tree"];
- findWord("worksheet")=="worksheet"
- findWord("workshe")=="works"
- findWord("workdesk")==false
4. test data
I used the default wordlist available on every linux system (/usr/share/dict/). The English wordlist contains 74137 unique words (filter out 1-letter, with apostrophe and lowercased) - the German wordlist has 327314 words. I chose 100 words containing / not containing in the list for benchmarking the access speed.
wordlist as a String
The shortest variant is putting the complete wordlist as a plain string in the loader.
- words.load("String", "aah aahed aahing aahs aal zyzzyvas zzz");
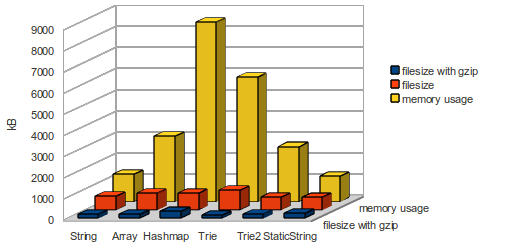
filesize for English wordlist: 660 kB (gzip: 195 kB) - loading time: 20ms
filesize for German wordlist: 4223 kB (gzip: 857 kB)
- findInString: function (word) {
- var data = this.data.String;
- while (word) {
- if (data.indexOf(word) !== -1) {
- return word;
- }
- word = word.substring(0, word.length - 1)
- }
- return false;
- }
Wow, searching a non-existing word with String.indexOf is quite expensive!
The memory usage (1.3 MB) is factor 2 then the plain file size (650 kB) because the JavaScript String is using utf-16.
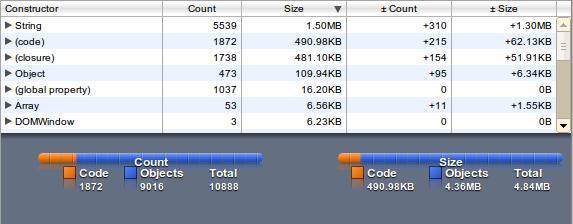
wordlist as plain Array
For a better search performance we can split the wordlist on server side and offer the split up wordlist (splitting in client side will double the memory usage).
- words.load("Array", ["aah","aahed","aahing","aahs","aal","zyzzyvas","zzz"]);
filesize for English wordlist: 805 kB (gzip: 200 kB) - loading time: 42ms
filesize for German wordlist: 4862 kB (gzip: 876 kB)
Searching in a sorted Array is simple binary search with O(log n).
- findInArray: function (word) {
- var data = this.data.Array;
- var i = Math.floor(data.length / 2);
- var jump = Math.ceil(i / 2);
- while (jump) {
- if (data[i] === word) return word;
- i = i + ((data[i] < word) * 2 - 1) * jump;
- jump = (jump === 1) ? 0 : Math.ceil(jump / 2);
- }
- if (word.indexOf(data[i - 1]) === 0) return data[i - 1];
- return (word.indexOf(data[i]) === 0) ? data[i] : "";
- }
The memory usage is factor 5 (String and Array) than the file size.
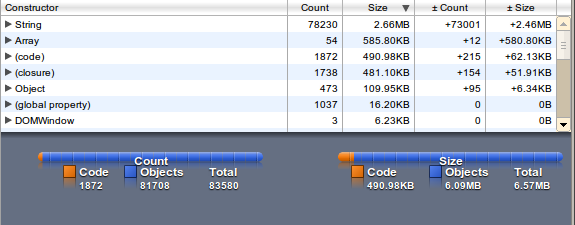
wordlist as Hashmap
Because binary search with many items is more expensive than key-access we can use a hashmap (or a native JavaScript Object). Accessing should be optimized and with stripping the " from ASCII key-names the file size is not longer than the Array variant.
- words.load("Hashmap", {zzz:1,aal:1,aahed:1,aah:1,aahing:1,aahs:1,zyzzyvas:1});
filesize for English wordlist: 797 kB (gzip: 325 kB) - loading time: 96ms
filesize for German wordlist: 5302 kB (gzip: 1804 kB)
Accessing the words in a hasmap is O(1), searching the word stem is O(m) (m is the maximum word length).
- findInHashmap: function (word) {
- var data = this.data.Hashmap;
- while (word) {
- if (word in data) {
- return word;
- }
- word = word.substring(0, word.length - 1)
- }
- return false;
- }
The memory usage is factor 10, the loading time factor 2 - but access to the words is quite fast (as expected).
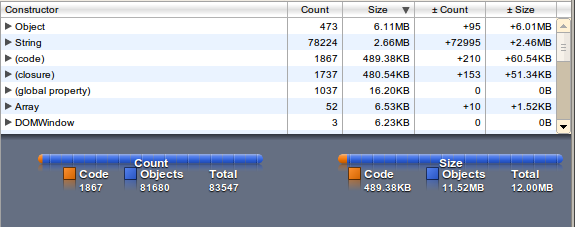
wordlist as Trie
An trie is a special tree data structure for searching ASCII data (mostly for similar words). Every letter is one node and realized as a recursive Object. We can save the file size by stripping the " in key-names (if this letter is a valid variable name in JavaScript).
- words.load("Trie", {a:{a:{h:{i:{n:{g:{$:1}}},s:{$:1},e:{d:{$:1}},$:1},l:{$:1}}},z:{y:{z:{z:{y:{v:{a:{s:{$:1}}}}}}},z:{z:{$:1}}}});
I run the Javascript unpacker and beautifier for better reading:
- words.load("Trie", {
- a: {
- a: {
- h: {
- i: {
- n: {
- g: {
- $: 1
- }
- }
- },
- s: {
- $: 1
- },
- e: {
- d: {
- $: 1
- }
- },
- $: 1
- },
- l: {
- $: 1
- }
- }
- },
- z: {
- y: {
- z: {
- z: {
- y: {
- v: {
- a: {
- s: {
- $: 1
- }
- }
- }
- }
- }
- }
- },
- z: {
- z: {
- $: 1
- }
- }
- }
- });
As you see this is the complete normalized version and has some useless subtrees in the example with 7 words. The structure would be better with many similar words. There exists many generators which offers better tries (John Resig did some work).
filesize for English wordlist: 950 kB (gzip: 142 kB) - loading time: 237ms
filesize for German wordlist: 4016 kB (gzip: 464 kB)
Searching words in a trie (including the word stem) is O(m) (m is the maximum word length).
- findInTrie: function (word) {
- var node = this.data.Trie;
- var result = "";
- for (var i = 0; i < word.length; i++) {
- if (node.$) result = word.substring(0, i);
- if (word[i] in node) node = node[word[i]];
- else
- return result;
- }
- return result;
- }
The memory usage is factor 8, the loading time factor 5 - but access to unknown words is quite fast (as expected).
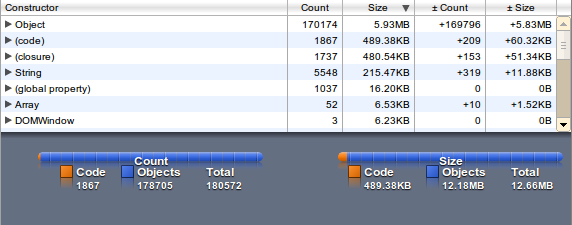
Trie-variant
Depending on your wordlist the file size can decreased if the most used starting letter are used for the level-1 key.
- words.load("Trie2", {
- aa: {
- hed: 1,
- h: 1,
- hing: 1,
- l: 1,
- hs: 1
- },
- zy: {
- zzyvas: 1
- },
- zz: {
- z: 1
- }
- }, 2);
In the English wordlist with 74137 unique words is the optimal split after 3 letter, in the German wordlist with 327314 words after 8 letter.
filesize for English wordlist: 599 kB (gzip: 204 kB) - loading time: 69ms
filesize for German wordlist: 3273 kB (gzip: 991 kB)
Searching the word in this 2-level trie (including the word stem) is O(m) like the hashmap variant (m is the maximum word length).
- findInTrie2: function(word) {
- var data = this.data.Trie2;
- while(word) {
- var first = word.substring(0, this.opt.Trie2);
- var second = word.substring(this.opt.Trie2);
- //console.info("word: "+word);
- if (word.length>this.opt.Trie2) {
- if (first in data && second in data[first])
- return word;
- }
- else {
- if (first in data) return word;
- }
- word = word.substring(0, word.length-1)
- }
- return false;
- }
staticString, ordered by word length
This data structure is offered by Mathias Nater (hyphenator.js at http://code.google.com/p/hyphenator/). All words ordered by length and concatenated into strings.
- words.load("StaticStr", {
- "8": "zyzzyvas",
- "3": "aahaalzzz", // three words concat
- "4": "aahs",
- "5": "aahed",
- "6": "aahing"
- });
filesize for English wordlist: 588 kB (gzip: 241 kB) - loading time: 18ms
filesize for German wordlist: 4203 kB (gzip: 991kB)
Searching the word in the static string map is a binary search on the m entries and result in O(log n * m) .
- findInStaticStr: function(word) {
- var data = this.data.StaticStr;
- var s, i, step;
- for (var len=word.length; len>1; len--)
- if (len in data) {
- i = Math.floor(data[len].length/(len*2));
- jump = Math.ceil(i/2);
- while (jump) {
- s = data[len].substring(i*len, i*len + len);
- if (s===word) return word;
- i = i + ((s<word)*2-1)*jump;
- jump=(jump===1)?0:Math.ceil(jump/2);
- }
- s1 = data[len].substring(i*len, (i+1)*len);
- s2 = data[len].substring((i+1)*len, (i+2)*len);
- if (s1.length===len && word.indexOf(s1)===0) return s1;
- if (s2.length===len && word.indexOf(s2)===len) return s2;
- }
- }
The file size, memory usage and loading time are better than the plain string (and the best in the competition). And the accessing time is fast enough. As you see this static string map variant dont make the heavy use of hashmaps and is the best solution for saving resources for mobile html apps.
conclusion and live benchmarks
- a hashmap (or plain JavaScript Object) needs much more memory than the pure String
- with gzip the file size differs only from 142 kB to 325 kB
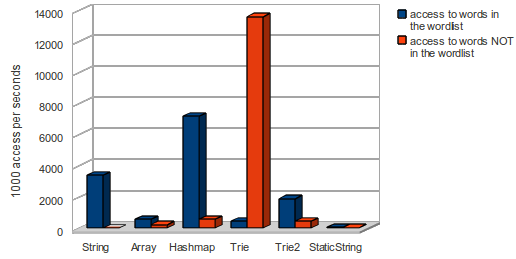
- the Trie data structure is perfect for finding words which are not in the wordlist.
- the hashmap and the string variant (with indexOf) is fine with known words in the wordlist
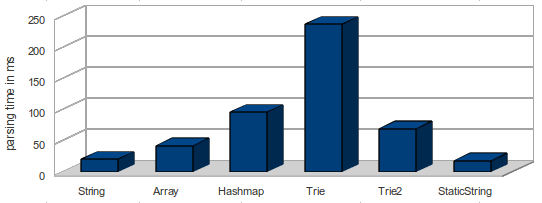
Parsing time on a Core I7 is significant - so it will on a mobile parser a NO-GO!
I included the benchmarking page as an iframe - feel free to load and run the benchmarks. Open your JavaScript console to see some debugging lines or play with the global words-object. The code can found at http://pyunitedcoders.appspot.com/words.js.
- Login to post comments